Hadoop Best Practices for Handling Structured Data - Transforming Hive Data. Suite offers to implement these practices as you develop your modern data integration solution on a Hadoop platform.
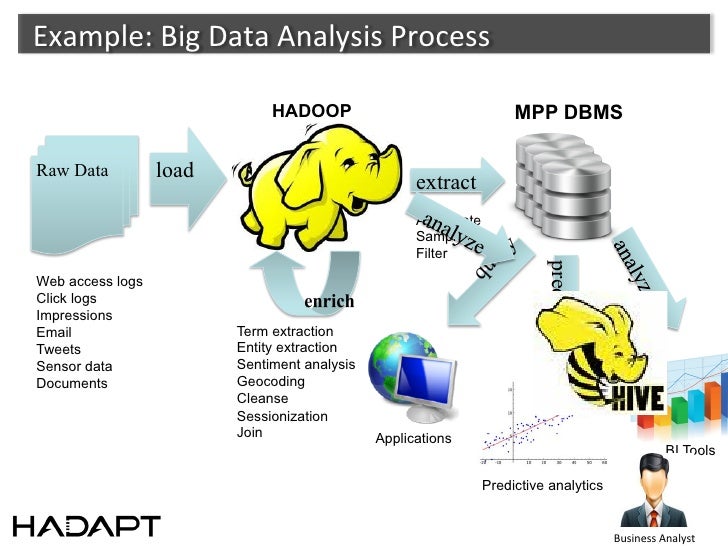 Analyzing Multi Structured Data
Analyzing Multi Structured Data
Nov 1 182334 dev_id03 user_id000 int_ip19801324 ext_ip6867014 src_port99 dest_port213 response_code5 Expected output.

Hadoop structured data example. Now with Hadoop it is possible to capture and store the logs. While this can waste space with needless column headers it is a simple way to start using structured data in HDFS. Pivotal pythian to mentioned a few.
Nov 1 182334 03. The following is an example HDFS directory structure that we use when implementing data warehouse on Hadoop ecosystem. Theres no data model in Hadoop itself.
Hadoop stores petabytes of data using HDFS. A fact table needs to be joined to a large dimension. In this tutorial you will use an semi-structured application log4j log file as input and generate a Hadoop MapReduce job that will report some basic statistics as output.
With Hadoop you can store data longer. One example is Order fact with Customer dimension. One of the immense things about Hadoop is that it provides a consistent easy on the pocket and comparatively a simpler framework for gathering confining and storing multiple data streams that was some years ago not feasible.
Hadoop File system HDFS HDFS is a Java-based file system that provides scalable and reliable data storage and it was designed to span large clusters of commodity servers. As on the given image above lets say the file size is 230 MB and the default block capacity is 64 MB is loaded into HDFS. Data warehouse is good when questions are known data domain and structure is defined Hadoop is great for seeking new meaning of data new types of insights Unique information parsing and interpretation Huge variety of data sources and domains When new insights are found and new structure defined Hadoop often takes.
Im trying to structure the un-structured data using PIG for doing some processing. As such the core components of Hadoop itself have no special capabilities for cataloging indexing or querying structured data. Developed by IBM in 1974 structured query language SQL is the programming language used to manage structured data.
The beauty of a general-purpose data storage system is that it can be extended for highly specific purposes. Additionally tools such as Hive and Impala allow you to define additional structure around your data in Hadoop. Ive used this approach many times and its a great stepping stone to more structured data.
IiiWebpages is an example of structured data. Because the volume of these logs can be very high not many organizations captured these. During these operations we dont normally think of what kind of applications we deal with and what types of data they process.
HDFS is a distributed file system which stores structured to unstructured data. HDFS has demonstrated production scalability of up to 200 PB of storage and a single cluster of 4500 servers supporting close to a billion files and blocks. Lets take an example of unstructured data analysis.
Excel spreadsheet that contains information about customers and purchases. Data is simply stored on the Hadoop cluster as raw files. Heres the sample of the data.
Email is an example of structured data iPresentations is an example of structured data ii. While all data in Hadoop rests in HDFS there are decisions around what the underlying storage manager should befor example whether you should use HBase or HDFS directly to store the data. Examples of structured data include dates names addresses credit card numbers etc.
There are various commands to perform different file operations. Applications that process large amounts of structured and semi-structured data in parallel across large clusters of machines in a very reliable and fault-tolerant manner. Pretty much everyone has dealt with booking a ticket via one of the airline reservation systems or withdrawing cash using an ATM.
By using a relational SQL database business users can quickly input search and manipulate structured data. If this is the. The spreadsheet is an another good example of structured data.
The typical structured data example. The file will be splitted in 3 blocks of 64 MB and 1 block of 38 MB. Let us take a look at some of the important Hadoop commands.
Searching and accessing information from such type of data is very easy. For example data stored in the relational database in the form of tables having multiple rows and columns. Since Hadoop provides storage at reasonable cost this type of data can be captured and stored.
User This folder will have the user specific configuration files. Taking an example consider unstructured data in Hadoop. One example would be website click logs.
One common example is to make each line a JSON document to add some structure. Pros and cons of structured data. Hadoop being an open-source project in numerous applications specific to videoaudio file processing image files analysis text analytics have being developed in market.
It provides redundant storage for files having humongous size. Ad Search for Hadoop example at MySearchExperts. Consider the Video data feed from a CCTV surveillance system of an enterprise.
List of Hadoop Commands. Find info on MySearchExperts.

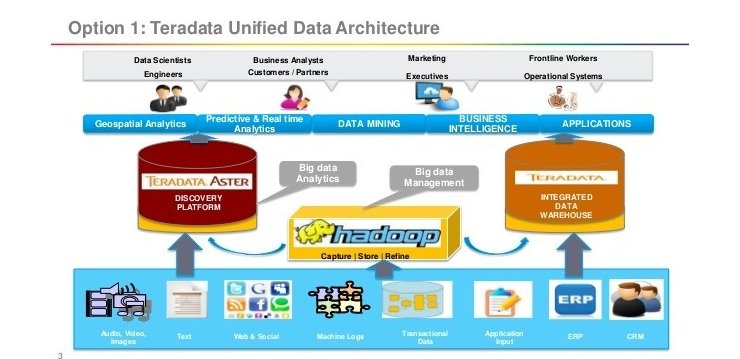 Improving Business Performance Using Hadoop
Improving Business Performance Using Hadoop
Architecture For Integrating Structured And Unstructured Data In Download Scientific Diagram

Post a Comment
Post a Comment